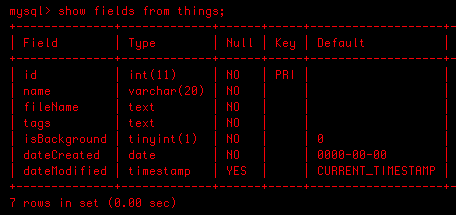
Solr is quite easy to setup once you understand it. It is much like any other database setup. So given the following the table, we have to mimic something similar in Solr. It need to know what is “stored” versus what is “indexed” as well as facets and many other options. I will explain more later. Here is my MySQL table representing ‘things’.
Okay. Simple enough right? So we want to do here is store most of this data; however, for facets we dont really need to store them. What does that mean? Well we want to be able to search through them and index them but when we ask for all columns of a given field it wont return this field. This will come into play later when I discuss faceting. Here is the schema.xml file for the above MySQL table:
Now that we are complete with our basic table structure we have to tell Solr a few things about our index. It wants to know the primary key, or in Solr terms, the unique key. Also we have to tell it our default search field.
Now we have one more very important variable that we have to tackle if want proper faceting on tags. We have to make sure that any time we write to the tags text field we also write to the tags string field. The difference is that the ‘tags’ field is stemmed, i.e. searching for ‘kids’ returns ‘kid’ and so forth. The ‘tagsFaceted’ field will return the whole words. One is human readable and the other is for the machines.
SOLR, a wrapper for Lucene, was developed by a fellow coworker at CNET. It has recently graduated from the Apache incubation cycle and is now a full fledge project. It not only does it wrap Lucene with a simpler interface it more importantly creates a Restful type of API. I only been using this for a few months now but I love it. It will be launching it into production at work and for my own personal project.
So what is SOLR/Lucene
Lucene is an indexing system, much like a database, except faster and narrower. Narrower? Well essentially an index is a single table with a primary key per entry. It allows extremely fast full text searching with stemming that other databases cannot handle, or even support. MySQL for example, especially MySQL 5 will fall over under heavy load no ifs-ands-or-buts. I’ve seen it happen at work in the lab as well as in production.
Lucene, as well as Solr, are built in Java but Solr needs a servlet container to run like Tomcat, Resin, WebLogic, etc. It runs “next to” your database. All the data in the Lucene index is the same as 1 table in your database. When you write to your DB you will write to Lucene (via SOLR). When you delete, same thing. Updating, yes. You get the point.
Faceting
Solr, and Lucene of course, also support faceting which is very powerful. You have seen this on many sites especially in the world of online shopping comparison. It allows you to see how many other entries also share the same common attributes. In the example of shopping comparison you can see how many other products are also, under 20 dollars, made of cotton, and from Amazon Marketplace. This is very powerful feature and it is perfect for allowing users to drill down through the data.
I will post more findings when I have the time, including configurations.
Wow. This was a lot more complicated than I thought. After several days of research and questions I finally discovered how to make this work. Its all about custom property editors. Please note that many-to-many relationships are not the best thing to use in a production environment. They dont scale well and they are not easy to manage. I later on replaced with Solr, my new favorite implementation.
In this example, many ‘things’ have many ‘tags’ and inversely many ‘tags’ have many ‘things’.
protected void initBinder(HttpServletRequest request, ServletRequestDataBinder binder) {
binder.registerCustomEditor(Set.class, “tags”, new CustomCollectionEditor(Set.class) {
protected Object convertElement(Object element) {
long id = NumberUtils.parseNumber((String) element, Long.class).longValue();
Tag tag = tagMgr.getTag(element.toString());
Recently I had to fabricate some nasty rewrite rules involving some unruly query parameters where if one was present do this, whereas if two were present do that, or if none were present redirect somewhere else. I had to step back after a few hours of work to try and look at this problem differently. All of sudden it became clear. Some code is omitted but here are two examples that I am using in production:
As you can see I am setting up gates or switches. The list went on and on and the order is highly important as you may notice, just as some ‘if’ blocks are (consider refactoring). In the case of a top-down script like mod_rewrite I feel this is not only acceptable but necessary to accomplish this task.
While having a few drinks with a buddy of mine at a local bar in San Francisco I met an editor for Jalopnik, a sister site for gawker.com. After talking to him for a while I mentioned my open source fuel injected 1973 BMW 2002 sitting out on the street. Next thing I know he is taking pictures of the car and taking down my info. A few days later some friends who read the site me this link featuring my car.
After months of planning, documenting, and gathering parts the project is finally complete (almost). I still have to ditch the distributor for a crank fired ignition system but this’ll do for now. As always, more details and exact plans can be found on the wiki
After 5 days of working on the fuel injection I am finally almost complete. Fortunately my friend let me use his garage for week which has been extremely helpful. I also had the help of my roommate. Right now are are stuck because my computer cannot get a signal from the coil telling it to fire. I have to do some more research but I am sure it will work.
My boss is a huge proponent to proper SEO standardization which means I have to be also. Every move I make, every URL I modify, every link I create it scrupulously examined. If him training me wasnt enough, he had the CEO from NetConcepts come in from Australia to teach us more tricks of the trade. Needless to say, I learned a hell of a lot. I will post more of my findings as I implement them.
I have just noticed that this site (based on WordPress) is using title tags incorrectly. Unlike H1 tags, tittle tags are read backwards in the eyes of Google. For example, on subcategory pages on this site, the titles read “John Clarke Mills >> Portfolio”. Ideally they would read something like this “Portfolio – John Clarke Mills”.
In a shopping comparison example, lets say you are looking for men’s jeans and you have drilled down based on these attributes or facets. The title should read something like “Jeans – Mens – myShoppingSite.com”. However, the H1 tag like the breadcrumb would read something like “Home – Men’s – Jeans”. Makes sense once you know it but kinda strange at first.
In the spirit of being open source, I have decided to convert my little BMW to Electronic Fuel Injection (EFI). What prompted this decision was a road trip to Chico when my car didnt perform as well due to the environment, i.e. the altitude. This is due the carburetor, a great invention that works incredibly well to this day, but for me, it wasnt enough. I liked the idea of being able to tune my car with a computer. Even while I’m driving! It sure beats taking the carbs apart over and over to change the jets . As always, I will be managing the project and researching on my wiki.
The MegaSquirt system was built by a bunch of Assembler engineers who realized that there was a place for open source in this industry. If I were to do the same via some of the closed source manufacturers I would be paying thousands with very limited resources. This is exactly how I view software in my day job. I am 100% open source in all of my environments. Now my car is the same. More info on this project can be found on the MegaSquirt website.